The previous post covered Building libffi for Windows x64 with Visual C++. In this post, I detail the instructions needed to build for the ARM64 platform (building the zero variant of the HotSpot JVM for the Windows ARM64 platform was my overall objective). I used the same Windows x64 machine for this build. As in the previous post, Visual C++ and MSYS are prerequisites. Get the sources from GitHub:
cd /c/repos
git clone https://github.com/libffi/libffi.git
cd libffi
git checkout v3.4.8
MSYS Prerequisites
Launch MSYS2 and install automake and libtool using these commands:
pacman -S automake
pacman -S libtool
The Visual C++ compiler needs to be available in the path as well. Run cl without any parameters to ensure the compiler is available. If it is available, it must be the ARM64 compiler to ensure we cross-compile! It most likely won’t be by default. If it isn’t, add it to the path as follows:
With the MSYS prerequisites installed, run the autogen.sh script:
user@machine /d/repos/libffi
$ ./autogen.sh
This creates a configure script in the root of the repository. Run it using bash. This command is the main difference between ARM64 and x86_64. Notice that I need to specify various include paths for the ARM64 compiler and linker that were not required in the x86_64 case.
Run make in the root of the repo. The generated LIB and DLL files should be in the aarch64-w64-mingw32/.libs/ subdirectory of the repo root. There will also be ffi.h and ffitarget.h include files in the aarch64-w64-mingw32/include/ subdirectory of the repo root. These 4 files are typically what will be required by other projects with a libffi dependency (like OpenJDK).
$ ls -1 aarch64-w64-mingw32/.libs/
libffi.la
libffi.lai
libffi_convenience.la
libffi_convenience.lib
libffi-8.dll*
libffi-8.exp
libffi-8.lib
$ ls -1 aarch64-w64-mingw32/include/
ffi.h
ffitarget.h
Makefile
Background Investigation Details
Investigating Configure Errors
My initial attempt at building libffi for Windows ARM64 started on the wrong path, based on this quote from libffi/libffi at v3.4.8.
To build static library for ARM64 with MSVC using visual studio solution, msvc_build folder have aarch64/Ffi_staticLib.sln required header files in aarch64/aarch64_include/
I thought this meant that it would be much faster for me to build libffi since I wouldn’t need all these bash configure stuff. The solution informed me that I needed to upgrade the toolset:
I then changed the architecture (in the Configuration Manager dropdown on the standard VS toolbox) from x64 to ARM64. There are a bunch of compiler errors!
1>D:\repos\libffi\src\closures.c(1015,30): error C2039: 'ftramp': is not a member of 'ffi_closure'
1> D:\repos\libffi\msvc_build\aarch64\aarch64_include\ffi.h(306,16):
1> see declaration of 'ffi_closure'
...
1>D:\repos\libffi\src\prep_cif.c(248,16): error C2065: 'FFI_BAD_ARGTYPE': undeclared identifier
How could a needed field be missing??!! I tried replacing ffi.h with the one from the x64 build but it was clearly wrong because it had architecture-specific code like this:
/* Specify which architecture libffi is configured for. */
#ifndef X86_WIN64
#define X86_WIN64
#endif
I then checked out the commit that added support for Windows AArch64.
I then tried to configure OpenJDK using this command but the configure script failed!
date; time bash configure --with-jvm-variants=zero --with-libffi=/cygdrive/c/repos/libffi --openjdk-target=aarch64-unknown-cygwin --with-debug-level=slowdebug --with-jtreg=/cygdrive/c/java/binaries/jtreg/jtreg-7.5.1+1 --with-gtest=/cygdrive/c/repos/googletest --with-extra-ldflags=-profile --with-boot-jdk=/cygdrive/c/java/binaries/jdk/x64/jdk-24+36; time /cygdrive/c/repos/scratchpad/scripts/java/cygwin/build-jdk.sh windows aarch64 slowdebug
At this point, I had the build tools installed with the C++ compiler in C:\progra~2\micros~3\2022\buildt~1\vc\tools\msvc\1443~1.348\bin\hostx64\arm64\cl.exe. I opened the VS Installer and installed the ARM64 compiler tools. This was necessary because this script was not present on my machine:
Running vcvarsamd64_arm64.bat initialized the environment for ‘x64_arm64’ (cross-compilation targeting ARM64). I then ran dumpbin to see which symbols were in the .lib file VS generated.
cd /d C:\repos\libffi
dumpbin /all /out:ffi-arm64.txt libffi.lib
cd /d D:\repos\libffi
dumpbin /all /out:ffi-x64.txt libffi.lib
The symbols were very different, which was my sign that I just needed to try building for ARM64 in MSYS2. I also upgraded VS some of the paths use 14.44 and others were 14.43. I started MSYS2 then added the arm64 compiler to the PATH. I tried the long path again but only the 8.3 filename format path worked.
export PATH="/c/Program\ Files/Microsoft\ Visual\ Studio/2022/Enterprise/VC/Tools/MSVC/14.44.35207/bin/Hostx64/arm64/:$PATH"
export PATH="$PATH:/c/Program\ Files/Microsoft\ Visual\ Studio/2022/Enterprise/VC/Tools/MSVC/14.44.35207/bin/Hostx64/arm64/"
# Only this one works.
$ export PATH="$PATH:/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/bin/Hostx64/arm64/"
$ where cl.exe
I then switched the repo back to v3.4.8 and ran autogen.sh. This time I specified the –target option to request a aarch64 build. See Specifying Target Triplets (Autoconf) for an overview of the target triplets.
I asked Copilot Which autoconf macro outputs “checking whether the C compiler works” and it said that’s the AC_PROG_CC macro. That string showed up in 3 spots in the codebase but they weren’t what I was looking for. The “checking for C compiler version” was in the generated configure script though.
# Provide some information about the compiler.
printf "%s\n" "$as_me:${as_lineno-$LINENO}: checking for C compiler version" >&5
set X $ac_compile
ac_compiler=$2
for ac_option in --version -v -V -qversion -version; do
{ { ac_try="$ac_compiler $ac_option >&5"
case "(($ac_try" in
*\"* | *\`* | *\\*) ac_try_echo=\$ac_try;;
*) ac_try_echo=$ac_try;;
esac
This explained where those odd arguments in the config.log snippet were coming from. The question was now how this was different from the x64 case where it just worked? The diff showed that I was actually still on 3.3-rc0 so I needed to rerun autogen.sh on v3.4.8. I didn’t think I needed the --target option since the correct compiler was selected (as far as I could tell from the --verbose output above).
The configure files were identical in both scenarios. However, there was a key difference in the config logs! Here is a snippet from the working x64 build’s config.log. Notice that the version detection errors were present in this case too (that was a red herring)!
configure:4679: /d/repos/libffi/msvcc.sh -m64 -version >&5
cl : Command line warning D9002 : ignoring unknown option '-version'
cl : Command line error D8003 : missing source filename
configure:4690: $? = 0
configure:4710: checking whether the C compiler works
configure:4732: /d/repos/libffi/msvcc.sh -m64 -DFFI_BUILDING_DLL conftest.c >&5
configure:4736: $? = 0
configure:4787: result: yes
configure:4679: /c/repos/libffi/msvcc.sh -marm64 -version >&5
cl : Command line warning D9002 : ignoring unknown option '-version'
cl : Command line error D8003 : missing source filename
configure:4690: $? = 0
configure:4710: checking whether the C compiler works
configure:4732: /c/repos/libffi/msvcc.sh -marm64 -DFFI_BUILDING_DLL conftest.c >&5
LINK : fatal error LNK1104: cannot open file 'MSVCRT.lib'
configure:4736: $? = 0
configure:4777: result: no
The linker error was really what I needed to address here. I created this conftest.c file to address the command line compilation issue:
int main (void)
{
return 0;
}
$ cl -MD -W3 conftest.c
Microsoft (R) C/C++ Optimizing Compiler Version 19.44.35207.1 for ARM64
Copyright (C) Microsoft Corporation. All rights reserved.
conftest.c
Microsoft (R) Incremental Linker Version 14.44.35207.1
Copyright (C) Microsoft Corporation. All rights reserved.
/out:conftest.exe
conftest.obj
LINK : fatal error LNK1104: cannot open file 'MSVCRT.lib'
How does OpenJDK get around this? Interestingly, this was when I noticed that the OpenJDK log also had all the version checking errors (-v -V –version, etc). This is the snippet from OpenJDK’s config.log (notice the -libpaths):
configure:105502: checking whether the C compiler works
configure:105524: /cygdrive/d/java/forks/TheShermanTanker/jdk/build/windows-aarch64-zero-slowdebug/fixpath exec /cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/tools/msvc/1443~1.348/bin/hostx64/arm64/cl.exe -I/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/tools/msvc/1443~1.348/include -I/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/tools/msvc/1443~1.348/atlmfc/include -I/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/auxili~1/vs/include -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/ucrt -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/um -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/shared -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/winrt -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/cppwinrt -I/cygdrive/c/progra~2/wi3cf2~1/netfxsdk/4.8/include/um -I/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/tools/msvc/1443~1.348/include -I/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/tools/msvc/1443~1.348/atlmfc/include -I/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/auxili~1/vs/include -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/ucrt -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/um -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/shared -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/winrt -I/cygdrive/c/progra~2/wi3cf2~1/10/include/100226~1.0/cppwinrt -I/cygdrive/c/progra~2/wi3cf2~1/netfxsdk/4.8/include/um conftest.c -link -libpath:/cygdrive/c/progra~1/mib055~1/2022/enterp~1/vc/tools/msvc/1443~1.348/lib/arm64 -libpath:/cygdrive/c/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64 -libpath:/cygdrive/c/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64 -profile >&5
Microsoft (R) C/C++ Optimizing Compiler Version 19.43.34810 for ARM64
Copyright (C) Microsoft Corporation. All rights reserved.
conftest.c
Microsoft (R) Incremental Linker Version 14.43.34810.0
Copyright (C) Microsoft Corporation. All rights reserved.
/out:conftest.exe
-libpath:c:\progra~1\mib055~1\2022\enterp~1\vc\tools\msvc\1443~1.348\lib\arm64
-libpath:c:\progra~2\wi3cf2~1\10\lib\100226~1.0\ucrt\arm64
-libpath:c:\progra~2\wi3cf2~1\10\lib\100226~1.0\um\arm64
-profile
conftest.obj
configure:105528: $? = 0
configure:105579: result: yes
Searching that codebase for libpath led to the location where the -libpath arguments are built in jdk/make/autoconf/toolchain_microsoft.m4. I should do the same thing and set the LDFLAGS.
$ cl -MD -W3 conftest.c -link -libpath:/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/lib/arm64 -libpath:/c/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64 -libpath:/c/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64
Microsoft (R) C/C++ Optimizing Compiler Version 19.44.35207.1 for ARM64
Copyright (C) Microsoft Corporation. All rights reserved.
conftest.c
Microsoft (R) Incremental Linker Version 14.44.35207.1
Copyright (C) Microsoft Corporation. All rights reserved.
/out:conftest.exe
-libpath:C:/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/lib/arm64
-libpath:C:/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64
-libpath:C:/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64
conftest.obj
That succeeded so I tried to set the LDFLAGS for libffi.
Looks like the other paths are being dropped by the script. Further inspection of the script reveals that it has a -L option for these libraries. I tried the -link option but something wasn’t working so I moved on to -L. These are the libraries I needed:
With the above command, the next issue was around cross compiling:
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
continue configure in default builddir "./x86_64-w64-mingw32"
....exec /bin/sh ../configure "--srcdir=.." "--enable-builddir=x86_64-w64-mingw32" "mingw32"
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
checking for gsed... sed
checking for a BSD-compatible install... /usr/bin/install -c
checking whether sleep supports fractional seconds... yes
checking filesystem timestamp resolution... 0.01
checking whether build environment is sane... yes
checking for a race-free mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking xargs -n works... yes
checking for gcc... /c/repos/libffi/msvcc.sh -marm64 -L /c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/lib/arm64 -L /c/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64 -L /c/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64
checking whether the C compiler works... yes
checking for C compiler default output file name... conftest.exe
checking for suffix of executables... .exe
checking whether we are cross compiling... configure: error: in '/c/repos/libffi/x86_64-w64-mingw32':
configure: error: cannot run C compiled programs.
If you meant to cross compile, use '--host'.
See 'config.log' for more details
At least this error message let me know what I needed to do to.
Next error after that change in the checking how to run the C++ preprocessor step, specifically error: C++ preprocessor "cl -nologo -EP" fails sanity check.
configure:14431: checking how to run the C++ preprocessor
configure:14498: result: cl -nologo -EP
configure:14512: cl -nologo -EP -DFFI_BUILDING_DLL conftest.cpp
conftest.cpp
conftest.cpp(12): fatal error C1034: limits.h: no include path set
configure:14512: $? = 2
configure: failed program was:
| /* confdefs.h */
| #define PACKAGE_NAME "libffi"
| #define PACKAGE_TARNAME "libffi"
| #define PACKAGE_VERSION "3.4.8"
| #define PACKAGE_STRING "libffi 3.4.8"
| #define PACKAGE_BUGREPORT "http://github.com/libffi/libffi/issues"
| #define PACKAGE_URL ""
| #define PACKAGE "libffi"
| #define VERSION "3.4.8"
| #define LT_OBJDIR ".libs/"
| /* end confdefs.h. */
| #include <limits.h>
| Syntax error
configure:14512: cl -nologo -EP -DFFI_BUILDING_DLL conftest.cpp
conftest.cpp
conftest.cpp(12): fatal error C1034: limits.h: no include path set
configure:14512: $? = 2
configure: failed program was:
| /* confdefs.h */
| #define PACKAGE_NAME "libffi"
| #define PACKAGE_TARNAME "libffi"
| #define PACKAGE_VERSION "3.4.8"
| #define PACKAGE_STRING "libffi 3.4.8"
| #define PACKAGE_BUGREPORT "http://github.com/libffi/libffi/issues"
| #define PACKAGE_URL ""
| #define PACKAGE "libffi"
| #define VERSION "3.4.8"
| #define LT_OBJDIR ".libs/"
| /* end confdefs.h. */
| #include <limits.h>
| Syntax error
configure:14547: error: in '/c/repos/libffi/aarch64-w64-mingw32':
configure:14549: error: C++ preprocessor "cl -nologo -EP" fails sanity check
See 'config.log' for more details
The configure script now completed! I had a feeling I would need to keep adding paths like this during the build process.
...
checking size of long double... 0
checking whether byte ordering is bigendian... no
checking assembler .cfi pseudo-op support... no
checking whether compiler supports pointer authentication... no
checking for _ prefix in compiled symbols... no
configure: versioning on shared library symbols is no
checking that generated files are newer than configure... done
configure: creating ./config.status
config.status: creating include/Makefile
config.status: creating include/ffi.h
config.status: creating Makefile
config.status: creating testsuite/Makefile
config.status: creating man/Makefile
config.status: creating doc/Makefile
config.status: creating libffi.pc
config.status: creating fficonfig.h
config.status: executing buildir commands
config.status: create top_srcdir/Makefile guessed from local Makefile
config.status: build in aarch64-w64-mingw32 (HOST=)
config.status: executing depfiles commands
config.status: executing libtool commands
config.status: executing include commands
config.status: executing src commands
real 1m29.429s
user 0m32.473s
sys 0m35.396s
Investigating Build Errors
Just as I suspected, there were build errors when I ran make. Specifically, 8 of these C1083 errors:
libtool: compile: /c/repos/libffi/msvcc.sh -marm64 -I "/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/include" -L "/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/lib/arm64" -L "/c/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64" -L "/c/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64" -DHAVE_CONFIG_H -I. -I.. -I. -I../include -Iinclude -I../src -DFFI_BUILDING_DLL -O2 -c ../src/prep_cif.c -DDLL_EXPORT -DPIC -o src/.libs/prep_cif.obj
C:/repos/libffi/include\ffi.h(66): fatal error C1083: Cannot open include file: 'stddef.h': No such file or directory
That file lives in C:\Program Files (x86)\Windows Kits\10\Include\10.0.22621.0\ucrt. The OpenJDK build includes these 5 paths (among many others) but I didn’t think I’d need the RT-related paths. I added the other 3 to the configure command then ran make again.
This search for commits did not yield anything but a web search of ksarm64.h – Search led me to the [Arm64/Windows] Missing ksarm64.h ? · Issue #7409 · dotnet/runtime GitHub issue, which said that ksarm64.h is part of the Windows SDK. ksarm64.h isn’t include in Windows SDK – Developer Community was the pointer about where it lives: c/progra~2/wi3cf2~1/10/include/100226~1.0/shared. I had excluded this path because I wanted a minimal set of include paths. This was the next command I tried. I should have exported these paths to an environment variable like I have at the top but I just kept moving forward.
libffi/msvcc.sh at v3.4.8 · libffi/libffi uses cygpath -ma, which outputs mixed absolute paths (windows form with forward slashes). Here is the corrected configure command (without the /cygdrive path prefixes):
This resolved the error about the spaces but then failed with:
Microsoft (R) Library Manager Version 14.44.35207.1
Copyright (C) Microsoft Corporation. All rights reserved.
LINK : fatal error LNK1181: cannot open input file 'src\.libs\prep_cif.obj'
Here’s the next iteration of the configure script:
...
libtool: compile: /c/repos/libffi/msvcc.sh -marm64 -I "/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/include" -I "/c/progra~2/wi3cf2~1/10/include/100226~1.0/ucrt" -I "/c/progra~2/wi3cf2~1/10/include/100226~1.0/um" -I "/c/progra~2/wi3cf2~1/10/include/100226~1.0/shared" "-L/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/lib/arm64" "-L/c/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64" "-L/c/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64" -DHAVE_CONFIG_H -I. -I.. -I. -I../include -Iinclude -I../src -O2 -c ../src/prep_cif.c -DDLL_EXPORT -DPIC -o src/.libs/prep_cif.obj
D:/repos/dups/libffi/src/prep_cif.c(219): warning C4273: 'ffi_prep_cif': inconsistent dll linkage
D:/repos/dups/libffi/src/prep_cif.c(225): warning C4273: 'ffi_prep_cif_var': inconsistent dll linkage
D:/repos/dups/libffi/src/prep_cif.c(257): warning C4273: 'ffi_prep_closure': inconsistent dll linkage
D:/repos/dups/libffi/src/prep_cif.c(268): warning C4273: 'ffi_get_struct_offsets': inconsistent dll linkage
...
libtool: compile: /c/repos/libffi/msvcc.sh -marm64 -I "/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/include" -I "/c/progra~2/wi3cf2~1/10/include/100226~1.0/ucrt" -I "/c/progra~2/wi3cf2~1/10/include/100226~1.0/um" -I "/c/progra~2/wi3cf2~1/10/include/100226~1.0/shared" "-L/c/Progra~1/MIB055~1/2022/Enterprise/VC/Tools/MSVC/14.44.35207/lib/arm64" "-L/c/progra~2/wi3cf2~1/10/lib/100226~1.0/ucrt/arm64" "-L/c/progra~2/wi3cf2~1/10/lib/100226~1.0/um/arm64" -DHAVE_CONFIG_H -I. -I.. -I. -I../include -Iinclude -I../src -O2 -c ../src/types.c -DDLL_EXPORT -DPIC -o src/.libs/types.obj
D:/repos/dups/libffi/src/types.c(77): error C2491: 'ffi_type_void': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(81): error C2491: 'ffi_type_uint8': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(82): error C2491: 'ffi_type_sint8': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(83): error C2491: 'ffi_type_uint16': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(84): error C2491: 'ffi_type_sint16': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(85): error C2491: 'ffi_type_uint32': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(86): error C2491: 'ffi_type_sint32': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(87): error C2491: 'ffi_type_uint64': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(88): error C2491: 'ffi_type_sint64': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(90): error C2491: 'ffi_type_pointer': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(92): error C2491: 'ffi_type_float': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(93): error C2491: 'ffi_type_double': definition of dllimport data not allowed
D:/repos/dups/libffi/src/types.c(111): error C2491: 'ffi_type_longdouble': definition of dllimport data not allowed
This seemed pretty odd, considering these errors didn’t show up for x64. I didn’t see any defines related to DLLs. Upon further inspection, I realized that I had removed the CPPFLAGS variable somewhere along the way! Restoring it finally got the job done! No make errors at all, phew!
I needed to build the zero variant of the HotSpot JVM for the Windows platform recently. libffi is one of the prerequisites for the zero variant. It provides “a portable, high level programming interface to various calling conventions.” I decided to build libffi/libffi at v3.4.8 since it looks like the latest version. I used a Windows x64 machine for this entire process. Visual C++ and MSYS need to be installed to do this. Launch MSYS2 and get the sources from GitHub:
Install automake and libtool using these commands:
pacman -S automake
pacman -S libtool
The Visual C++ compiler needs to be available in the path as well. Run cl without any parameters to ensure the compiler is available. It most likely won’t be by default. If it isn’t, add it to the path as follows:
Note that the name of the Visual C++ linker is link.exe, which clashes with the built in “link” command. Prepending the C++ compiler path means that the built-in link command will not be available. Appending the C++ compiler path means that the linker cannot be invoked without specifying its full path.
Generating the configure file
With the MSYS prerequisites installed, run the autogen.sh script:
user@machine /d/repos/libffi
$ ./autogen.sh
This creates a configure script in the root of the repository. Run it using bash:
Running configure takes about a minute and a half on my 24-core (32 logical processor) machine with 128GB RAM.
Building the Source Code
Simply run make in the root of the repo. The generated LIB and DLL files should be in the x86_64-w64-mingw32/.libs/ subdirectory of the repo root. There will also be ffi.h and ffitarget.h include files in the x86_64-w64-mingw32/include/ subdirectory of the repo root. These 4 files are typically what will be required by other projects with a libffi dependency (like OpenJDK).
$ ls -1 x86_64-w64-mingw32/.libs/
libffi.la
libffi.lai
libffi_convenience.la
libffi_convenience.lib
libffi-8.dll*
libffi-8.exp
libffi-8.lib
$ ls -1 x86_64-w64-mingw32/include/
ffi.h
ffitarget.h
Makefile
My Motivation for Building libffi
I was trying to configure an OpenJDK build (at commit c3de94cee12471) using this command line:
...
checking if hsdis should be bundled... no
checking for --enable-libffi-bundling... disabled, default
checking for LIBFFI... checking for ffi.h... no
configure: error: Could not find libffi!
configure exiting with result code 1
...
checking for --enable-libffi-bundling... disabled, default
checking if libffi works... no
configure: error: Found libffi but could not link and compile with it.
configure exiting with result code 1
This was my hint that I probably need to build libffi first. libffi/README.md at v3.4.8 · libffi/libffi explains that the configure script can be generated by running autogen.sh. I first need to fix the line endings. This copilot prompt “convert all existing files in a repo from windows to unix line endings” gets me the solution:
# Tells Git to convert CRLF to LF on commit
# but not the other way around on checkout.
git config core.autocrlf input
# resets the working directory and re-checks
# out the files using the current core.autocrlf setting
git reset --hard
Now autogen.sh can be executed. I didn’t read the instructions all the way through to see what prerequisites are required. Even so, which ones can I get away without?
user@machine /cygdrive/d/repos/libffi
$ ./autogen.sh
autoreconf-2.71: export WARNINGS=
autoreconf-2.71: Entering directory '.'
autoreconf-2.71: configure.ac: not using Gettext
autoreconf-2.71: running: aclocal -I m4
Can't exec "aclocal": No such file or directory at /usr/share/autoconf2.7/Autom4te/FileUtils.pm line 274.
autoreconf-2.71: error: aclocal failed with exit status: 1
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
continue configure in default builddir "./x86_64-w64-mingw32"
....exec /bin/sh ../configure "--srcdir=.." "--enable-builddir=x86_64-w64-mingw32" "mingw32"
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
checking for gsed... sed
checking for a BSD-compatible install... /usr/bin/install -c
checking whether sleep supports fractional seconds... yes
checking filesystem timestamp resolution... 0.01
checking whether build environment is sane... yes
checking for a race-free mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking xargs -n works... yes
checking for gcc... /d/repos/libffi/msvcc.sh -m64
checking whether the C compiler works... no
configure: error: in '/d/repos/libffi/x86_64-w64-mingw32':
configure: error: C compiler cannot create executables
See 'config.log' for more details
In Cygwin, that command failed with “configure: error: cannot run /bin/sh ./config.sub“. What could be going wrong in the configure script? M365 Copilot prompt: “change build system type in msys2” refers to gcc – Configuration x86_64-pc-msys not supported – Stack Overflow but those flags seem unnecessary given my platform. I tried removing some of the compiler setting flags to no avail:
$ time bash configure CPPFLAGS="-DFFI_BUILDING_DLL" CPP="cl -nologo -EP" CXXCPP="cl -nologo -EP" --disable-docs --prefix=/d/temp/libffi
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
continue configure in default builddir "./x86_64-w64-mingw32"
....exec /bin/sh ../configure "--srcdir=.." "--enable-builddir=x86_64-w64-mingw32" "mingw32"
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
checking for gsed... sed
checking for a BSD-compatible install... /usr/bin/install -c
checking whether sleep supports fractional seconds... yes
checking filesystem timestamp resolution... 0.01
checking whether build environment is sane... yes
checking for a race-free mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking xargs -n works... yes
checking for gcc... no
checking for cc... no
checking for cl.exe... no
checking for clang... no
configure: error: in '/d/repos/libffi/x86_64-w64-mingw32':
configure: error: no acceptable C compiler found in $PATH
See 'config.log' for more details
The config.log file is in the x86_64-w64-mingw32 folder in the repo root. What I should have verified is that I could run cl.exe in MSYS before trying any of this stuff. That was the primary reason for launch ucrt64.exe from a developer command prompt. Unfortunately, that didn’t work for whatever reason.
user@machine UCRT64 /d/repos/libffi
$ cl
-bash: cl: command not found
user@machine UCRT64 /d/repos/libffi
$ echo $PATH
/ucrt64/bin:/usr/local/bin:/usr/bin:/bin:/c/Windows/System32:/c/Windows:/c/Windows/System32/Wbem:/c/Windows/System32/WindowsPowerShell/v1.0/:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl
I tried manually fixing the path as follows but this didn’t work (cl.exe could still not be found):
The dir command can show the short name equivalents of a file name, e.g. dir /x C:\Program Files.
dir /x C:\
...
05/24/2025 11:42 AM <DIR> PROGRA~1 Program Files
04/09/2025 01:31 AM <DIR> PROGRA~2 Program Files (x86)
...
dir /x "C:\Program Files"
11/30/2023 04:40 PM <DIR> MIB055~1 Microsoft Visual Studio
Sure enough, I could now find cl.exe and the configure script worked!
$ where cl.exe
C:\Program Files\Microsoft Visual Studio\2022\Enterprise\VC\Tools\MSVC\14.43.34808\bin\Hostx64\x64\cl.exe
$ bash configure \
CC="/d/repos/libffi/msvcc.sh -m64" \
CXX="/d/repos/libffi/msvcc.sh -m64" \
CPPFLAGS="-DFFI_BUILDING_DLL" \
LD=link CPP="cl -nologo -EP" CXXCPP="cl -nologo -EP" \
--disable-docs \
--prefix=/d/temp/libffi
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
continue configure in default builddir "./x86_64-w64-mingw32"
....exec /bin/sh ../configure "--srcdir=.." "--enable-builddir=x86_64-w64-mingw32" "mingw32"
configure: loading site script /etc/config.site
checking build system type... x86_64-w64-mingw32
checking host system type... x86_64-w64-mingw32
checking target system type... x86_64-w64-mingw32
checking for gsed... sed
checking for a BSD-compatible install... /usr/bin/install -c
checking whether sleep supports fractional seconds... yes
checking filesystem timestamp resolution... 0.01
checking whether build environment is sane... yes
checking for a race-free mkdir -p... /usr/bin/mkdir -p
checking for gawk... gawk
checking whether make sets $(MAKE)... yes
checking whether make supports nested variables... yes
checking xargs -n works... yes
checking for gcc... /d/repos/libffi/msvcc.sh -m64
checking whether the C compiler works... yes
checking for C compiler default output file name... conftest.exe
checking for suffix of executables... .exe
checking whether we are cross compiling... no
checking for suffix of object files... obj
checking whether the compiler supports GNU C... no
checking whether /d/repos/libffi/msvcc.sh -m64 accepts -g... yes
checking for /d/repos/libffi/msvcc.sh -m64 option to enable C11 features... unsupported
checking for /d/repos/libffi/msvcc.sh -m64 option to enable C99 features... unsupported
checking for /d/repos/libffi/msvcc.sh -m64 option to enable C89 features... unsupported
checking whether /d/repos/libffi/msvcc.sh -m64 understands -c and -o together... yes
checking whether make supports the include directive... yes (GNU style)
checking dependency style of /d/repos/libffi/msvcc.sh -m64... none
checking whether the compiler supports GNU C++... no
checking whether /d/repos/libffi/msvcc.sh -m64 accepts -g... yes
checking for /d/repos/libffi/msvcc.sh -m64 option to enable C++11 features... unsupported
checking for /d/repos/libffi/msvcc.sh -m64 option to enable C++98 features... unsupported
checking dependency style of /d/repos/libffi/msvcc.sh -m64... none
checking dependency style of /d/repos/libffi/msvcc.sh -m64... none
checking for grep that handles long lines and -e... /usr/bin/grep
checking for egrep... /usr/bin/grep -E
checking how to print strings... printf
checking for a sed that does not truncate output... /usr/bin/sed
checking for fgrep... /usr/bin/grep -F
checking for non-GNU ld... link
checking if the linker (link) is GNU ld... no
checking for BSD- or MS-compatible name lister (nm)... /usr/bin/nm -B
checking the name lister (/usr/bin/nm -B) interface... BSD nm
checking whether ln -s works... no, using cp -pR
checking the maximum length of command line arguments... 8192
checking how to convert x86_64-w64-mingw32 file names to x86_64-w64-mingw32 format... func_convert_file_msys_to_w32
checking how to convert x86_64-w64-mingw32 file names to toolchain format... func_convert_file_msys_to_w32
checking for link option to reload object files... -r
checking for file... file
checking for objdump... objdump
checking how to recognize dependent libraries... file_magic ^x86 archive import|^x86 DLL
checking for dlltool... dlltool
checking how to associate runtime and link libraries... func_cygming_dll_for_implib
checking for ranlib... ranlib
checking for ar... ar
checking for archiver @FILE support... @
checking for strip... strip
checking command to parse /usr/bin/nm -B output from /d/repos/libffi/msvcc.sh -m64 object... ok
checking for sysroot... no
checking for a working dd... /usr/bin/dd
checking how to truncate binary pipes... /usr/bin/dd bs=4096 count=1
checking for mt... no
checking if : is a manifest tool... no
checking for stdio.h... yes
checking for stdlib.h... yes
checking for string.h... yes
checking for inttypes.h... yes
checking for stdint.h... yes
checking for strings.h... no
checking for sys/stat.h... yes
checking for sys/types.h... yes
checking for unistd.h... no
checking for dlfcn.h... no
checking for objdir... .libs
checking for /d/repos/libffi/msvcc.sh -m64 option to produce PIC... -DDLL_EXPORT -DPIC
checking if /d/repos/libffi/msvcc.sh -m64 PIC flag -DDLL_EXPORT -DPIC works... yes
checking if /d/repos/libffi/msvcc.sh -m64 static flag works... yes
checking if /d/repos/libffi/msvcc.sh -m64 supports -c -o file.obj... yes
checking if /d/repos/libffi/msvcc.sh -m64 supports -c -o file.obj... (cached) yes
checking whether the /d/repos/libffi/msvcc.sh -m64 linker (link) supports shared libraries... yes
checking dynamic linker characteristics... Win32 ld.exe
checking how to hardcode library paths into programs... immediate
checking whether stripping libraries is possible... yes
checking if libtool supports shared libraries... yes
checking whether to build shared libraries... yes
checking whether to build static libraries... yes
checking how to run the C++ preprocessor... cl -nologo -EP
checking whether the /d/repos/libffi/msvcc.sh -m64 linker (link) supports shared libraries... no
checking for /d/repos/libffi/msvcc.sh -m64 option to produce PIC... -DDLL_EXPORT -DPIC
checking if /d/repos/libffi/msvcc.sh -m64 PIC flag -DDLL_EXPORT -DPIC works... yes
checking if /d/repos/libffi/msvcc.sh -m64 static flag works... yes
checking if /d/repos/libffi/msvcc.sh -m64 supports -c -o file.obj... yes
checking if /d/repos/libffi/msvcc.sh -m64 supports -c -o file.obj... (cached) yes
checking whether the /d/repos/libffi/msvcc.sh -m64 linker (link) supports shared libraries... no
checking dynamic linker characteristics... Win32 ld.exe
checking how to hardcode library paths into programs... immediate
checking for readelf... readelf
checking size of size_t... 8
checking for C compiler vendor... microsoft
checking whether C compiler accepts -O2... yes
checking CFLAGS for most reasonable warnings...
checking whether to enable maintainer-specific portions of Makefiles... no
checking for sys/memfd.h... no
checking for memfd_create... no
checking for egrep... (cached) /usr/bin/grep -E
checking for memcpy... no
checking for alloca.h... no
checking size of double... 8
checking size of long double... 8
checking whether byte ordering is bigendian... no
checking assembler .cfi pseudo-op support... no
checking assembler supports pc related relocs... yes
checking whether compiler supports pointer authentication... no
checking for _ prefix in compiled symbols... no
configure: versioning on shared library symbols is no
checking that generated files are newer than configure... done
configure: creating ./config.status
config.status: creating include/Makefile
config.status: creating include/ffi.h
config.status: creating Makefile
config.status: creating testsuite/Makefile
config.status: creating man/Makefile
config.status: creating doc/Makefile
config.status: creating libffi.pc
config.status: creating fficonfig.h
config.status: executing buildir commands
config.status: create top_srcdir/Makefile guessed from local Makefile
config.status: build in x86_64-w64-mingw32 (HOST=)
config.status: executing depfiles commands
config.status: executing libtool commands
config.status: executing include commands
config.status: executing src commands
I could now run make as instructed by the readme. Here is the tail of the resulting output:
I manually copied these files to set up the libffi repo for building OpenJDK (the expected LIB filename does not have the -8 suffix by default). I’m guessing make install or something like that is the proper way to do this but I had what I needed so this was good enough for me.
I tested this file to ensure I could compile it. The linking step failed (cl.exe without the -c option).
$ cl -c -I include ffi_test.c
Microsoft (R) C/C++ Optimizing Compiler Version 19.43.34810 for x64
Copyright (C) Microsoft Corporation. All rights reserved.
ffi_test.c
$ cl -I include ffi_test.c
Microsoft (R) C/C++ Optimizing Compiler Version 19.43.34810 for x64
Copyright (C) Microsoft Corporation. All rights reserved.
ffi_test.c
Microsoft (R) Incremental Linker Version 14.43.34810.0
Copyright (C) Microsoft Corporation. All rights reserved.
/out:ffi_test.exe
ffi_test.obj
ffi_test.obj : error LNK2019: unresolved external symbol __imp_ffi_call referenced in function main
ffi_test.exe : fatal error LNK1120: 1 unresolved externals
I tried manually running link.exe but this failed because the wrong link.exe is called.
$ where link.exe
C:\software\msys64\usr\bin\link.exe
C:\Program Files\Microsoft Visual Studio\2022\Enterprise\VC\Tools\MSVC\14.43.34808\bin\Hostx64\x64\link.exe
Prepending the compiler path to $PATH resolved this.
$ cl -I include ffi_test.c -link -libpath:lib libffi.lib
Microsoft (R) C/C++ Optimizing Compiler Version 19.43.34810 for x64
Copyright (C) Microsoft Corporation. All rights reserved.
ffi_test.c
Microsoft (R) Incremental Linker Version 14.43.34810.0
Copyright (C) Microsoft Corporation. All rights reserved.
/out:ffi_test.exe
-libpath:lib
libffi.lib
ffi_test.obj
$ ./ffi_test.exe
At this point, things were in good enough shape to build OpenJDK. However, I could not successfully run bash configure ... in Cygwin (to build OpenJDK) now. Perhaps it’s because I had been mucking around with the Cygwin setup. I tried removing automake and libtool but that didn’t fix the problem.
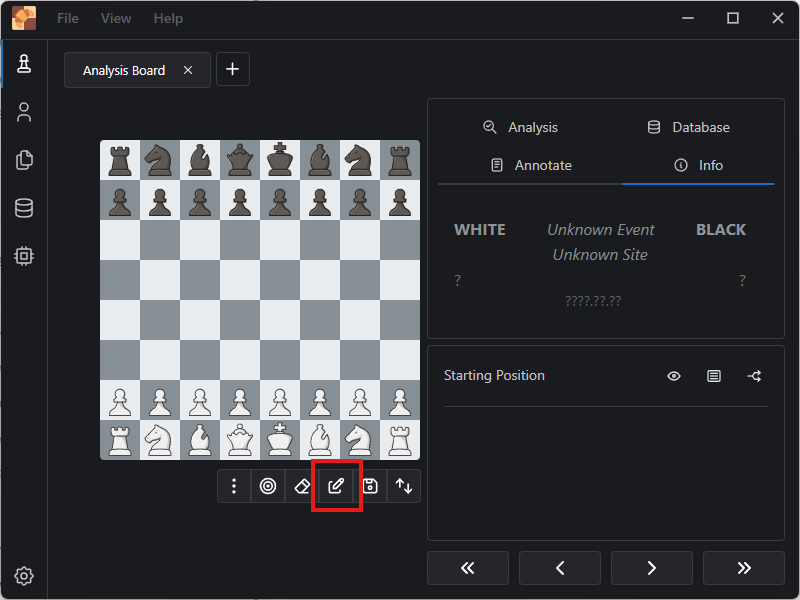
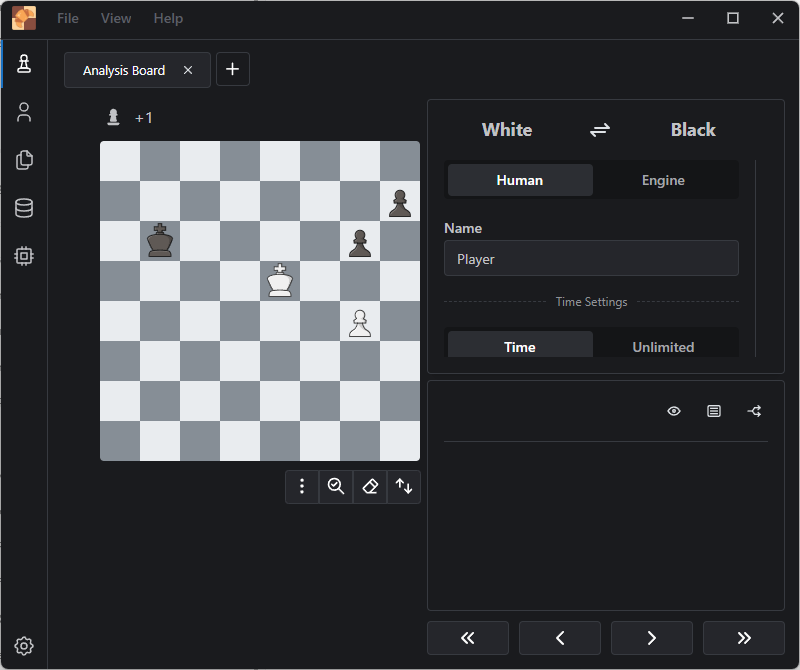
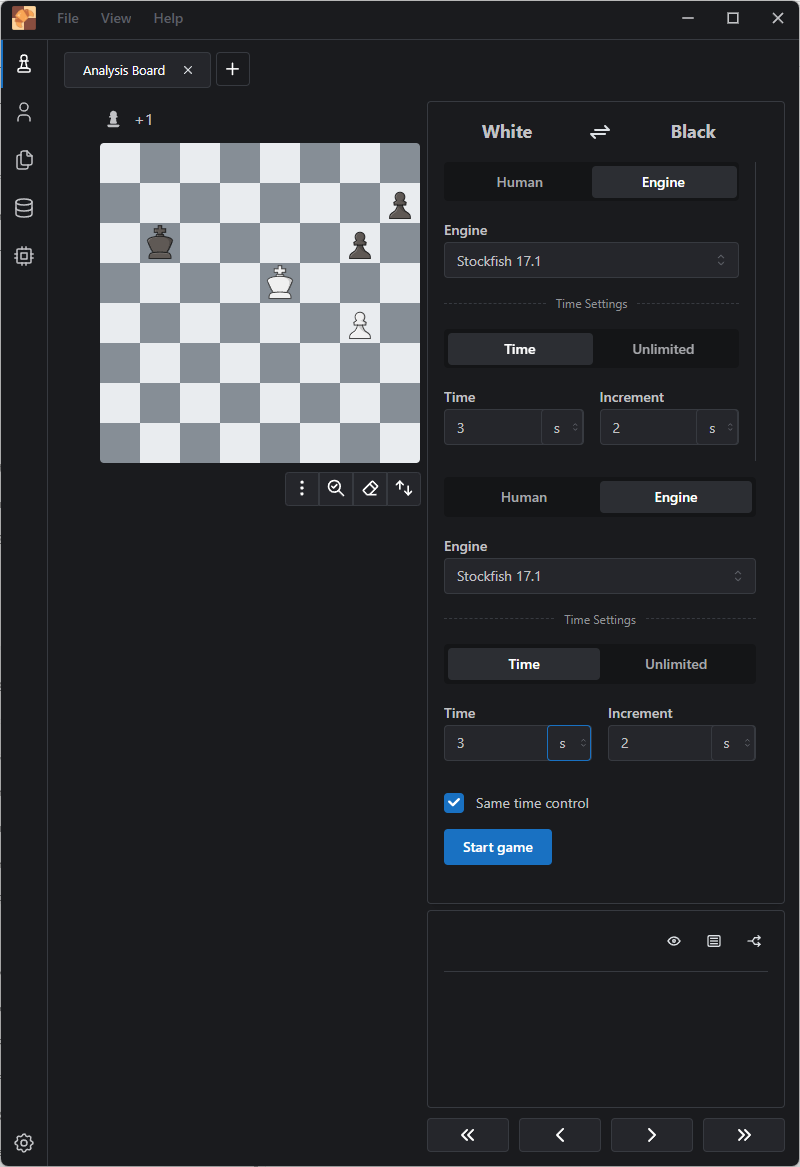
The “Analysis Board” command looks like the place to enter it. Click on the “Edit Position” button.
En Croissant Analysis Board Window
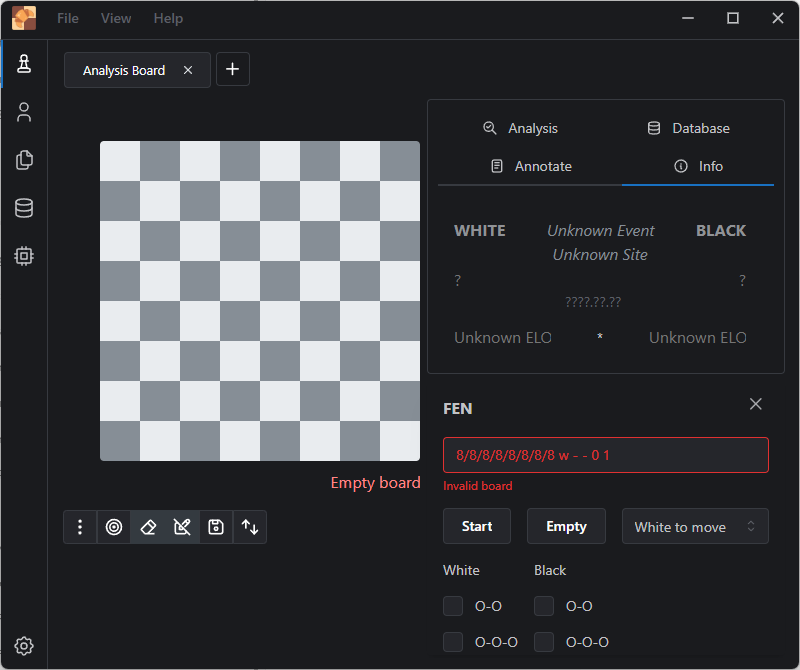
A FEN section appears with a textbox for your FEN. You can click on the EMPTY button to clear the board.
En Croissant Edit Position Window
I pasted my FEN into the FEN position text box then tabbed out of it and it just reverts to the empty board. Very unintuitive behavior – I accidentally discover that I need to press ENTER in that text box to accept my new position. An error appears about this being an invalid position. It would have been nice to have this validation happen instead of deleting my entry on TAB.
Invalid board
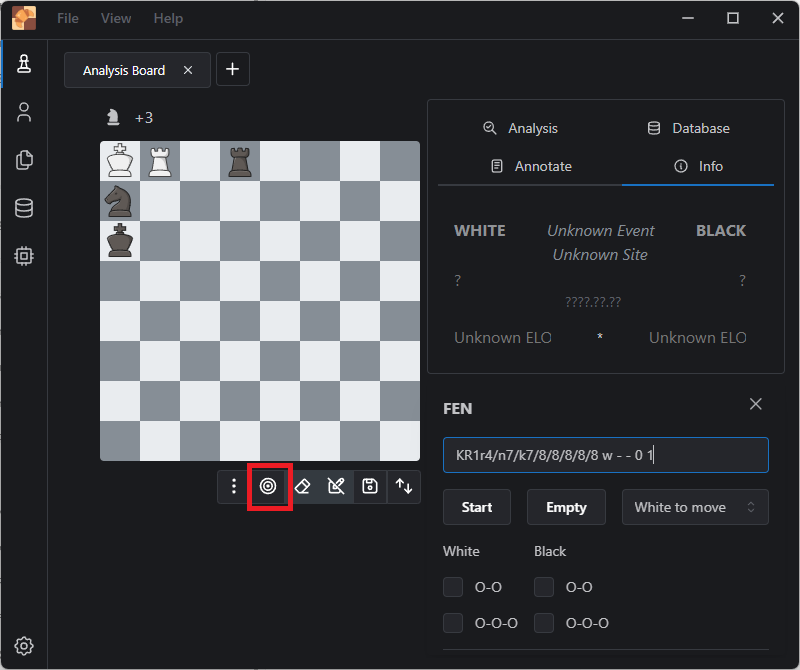
This is the corrected FEN:
KR1r4/n7/k7/8/8/8/8/8 w - - 0 1
This leaves me confident that I get the computer to help me analyze this position.
I select “C:\software\stockfish-windows-x86-64-avx2\stockfish\stockfish-windows-x86-64-avx2.exe” as per the wiki.
Add EngineStockfish 17.1 Engine Added
Now that I’ve set the engine to play, why aren’t the arrows labeled? I actually switched to Arena (see below) before returning with a renewed determination to get this to work. On the “Play from Here” screen, notice that the Engine button now displays Stockfish 17.1. Perhaps it’s the UI that’s confusing, looks like a bunch of controls just dumped into a panel. Switch both controls to Engine and adjust the time as desired. I’m using a 3s limit to keep things moving. Finally, click on “Start Game” and watch the engine battle itself.
Here are a few other FEN positions (from various Facebook posts) to play with:
KR1r4/n7/k/8/8/8/8/8 w - - 0 0
kr6/1r1N4/2Q5/8/8/8/8/K7 w - - 0 0
8/7p/1k4p1/4K3/6P1/8/8/8 w - - 0 0
k7/b7/2K5/4B3/8/8/8/Q7 w - - 0 0
Arena (3.5.1)
I had actually installed Arena before En Croissant but didn’t like that it wasn’t open source. I initially struggled getting the engine to play the game in En Croissant and went back to Arena.
Arena 3.5.1 Setup Wizard
I was pleasantly surprised that I could just load the FEN by going to Position > Load FEN from clipboard then have the computer play by going to Game > Move Now.
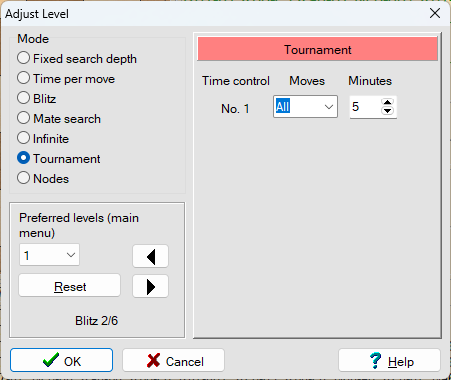
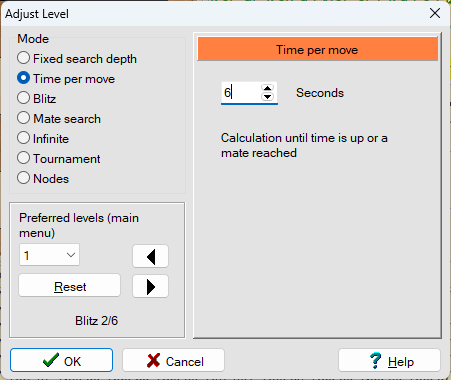
However, I didn’t like how long it took to make a move. After some exploration, I found that I could go to Levels > Adjust and change from Tournament mode to Time per move mode. It was ironic that I was using Arena without Stockfish for my analysis but still wanted to document my exploration of En Croissant. Perhaps it was this experience with the time setting in Arena that allowed me to adjust the time settings for the engine in En Croissant and actually see the Stockfish engine in action!
Improvements?
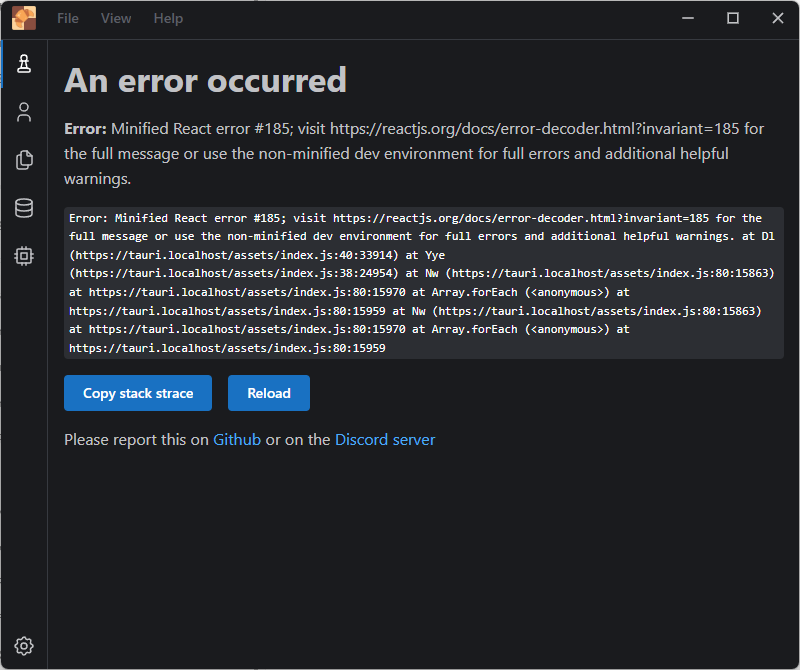
I wonder if I could add this Load FEN from clipboard option to En Croissant since it is open source. Such a command should automatically open the Analysis Board window. As I’m wrapping up this post, I just noticed the error below when I switched back to the En Croissant window.
Minified React Error
Making that UI change could be a good entry for me into the React world.
Cellular networks are a ubiquitous part of modern daily life. The history of cellular technology is definitely worth knowing, even if only at the high level presented in this video on the Evolution of Mobile Standards (1G, 2G, 3G, 4G, and 5G).
Evolution of Mobile Standards [1G, 2G, 3G, 4G, 5G]
2G introduced digital modulation and came in variants like TDMA, CDMA, and GSM. 3G uses spread spectrum in the radio portion of the network whereas 4G uses Orthogonal Frequency Division Mutiplexing (OFDM). 4G also separates the user and control planes whereas they were on the same hardware in 3G (and therefore couldn’t scale independently). The following videos from Sunny Classroom are brief but helpful explanations of these communications concepts.
FHSS – Frequency Hopping Spread Spectrum
DSSS – Direct Sequence Spread Spectrum
OFDM – Orthogonal Frequency Division Multiplexing
5G offers lower end-to-end latency and higher uplink and downlink throughput than 4G because it has more bands (low, mid, and high) vs just low and high with 4G. It is also a programmable network, which lets developers access network stats via APIs.
Mobility
The discussion in the class proceeded to mobility, introducing the concept of cellular handoff, which can broadly be classified into mobile assisted and mobile controlled handover. See Handoff in Wireless Mobile Networks for more details. Another classification of types of handover is based on when the UE disconnects from one cell: hard handoff vs soft handoff. Soft handoff ensures that calls are not dropped. The professor was drawing hexagonal cells when illustrating these and I realized I had no idea why they are hexagonal. Here’s why:
antennas in a coverage area are in a hexagonal pattern… because it requires fewer cells to represent a hexagon compared to triangle or square – meaning network carriers can cover a wider area with less base stations. – The Fundamentals of Cellular System Design
An interesting aspect of the LTE packet core is that a 5G base station can be attached to it. Contrast this mode, known as 5G non-standalone to 5G standalone mode, where a 5G radio is connected to a 5G packet core. See this post on Non-standalone and Standalone: two standards-based paths to 5G for a detailed review of these modes. One advantage of the 5G packet core is that it allows for cloud-based implementations. The Boost Mobile Network, for example, is 100% implemented in the cloud. Is AWS set to flex cloud on telecom? has a discussion of such a transition (to the cloud) in the telecom space.
The antennas used on the base stations can be of multiple types, e.g. SISO and MIMO. MIMO Antennas Explained: An In-Depth Guide provides more details on the differences between these designs. A key benefit of MIMO is that it eliminates performance degradation caused by multipath wave propagation.
We also dug into the LTE and 5G network evolution, from network deployment, to network growth, then finally coverage and capacity optimization. Deployment may involve dual-radio in UEs and EPC capabilities to support interoperability with earlier generations like 2G/3G. 5G is currently in the deployment phase since 5G SA has not yet been fully rolled out. Network growth may involve cell splitting in the RAN for capacity as well as expansion of the core network. Coverage and capacity optimization may involve spectrum aggregation, advanced network topologies, and advanced antenna techniques.
The continued growth in application and device diversity, RAN complexity, and QoS variance is making networks more complex and thus harder to optimize under the current network management paradigm. Self-organizing networks (SON) were designed to address this problem. Here is an overview of SON.
3GPP SON Series: An Introduction to Self-Organizing Networks (SON)
SON is used to set many required configuration parameters when introducing a new eNB or gNB to a network e.g. IP addresses from DHCP, transmit power, beam width, supported connections, connecting to neighboring base stations via the X2 (4G) or XN (5G) connection, etc. SON can also be used for driving energy savings by shutting down carriers when less capacity is required e.g. in the middle of the night (without dropping emergency calls). Another application is coverage and capacity optimization, which involves adjusting transmission power and continuously adjusting antenna tilt to increase capacity (thus decreasing coverage) or to increase coverage (thus decreasing capacity). Mobility handover optimization is also required to avoid too early/too late handover or a ping pong between base stations. The SON architecture can be centralized, distributed, or hybrid.
5G
Finally, we took a look at 5G technology, which has much lower latencies, much higher throughput, and high capacity. Some of the key technologies I learn about include Fixed Wireless Access, in which the UE does not move, and mmWave. More info on the latter is available at What is mmWave and how does it relate to 5G? 5G also supports modified air interfaces (modified OFDM), massive MIMO, device-to-device communication, separated user and control planes, and network virtualization.
An important capability that 5G introduced is positioning, which has many potential use cases e.g. industrial, automotive, and AR/VR. See 5G positioning: What you need to know for more details. In the industrial setting, for example, 5g all in one boxes are deployed in the 5G private networks. They have a base station and a packet core in a single piece of hardware, e.g. RAK All-in-One 5G box (the first one in the search results).
The 5G core network architecture is significantly different from the LTE packet core (eNB, SGW, PGW, MME, HSS, and PCRF). It moved to a service based architecture where microservices expose functionality via APIs. This makes the 5G network programmable and extensible. This 5G System Overview covers the overall 5G architecture. These are a few of the 5G components:
Network Slice Selection Function (NSSF), which allocates slices to users
Authentication Server Function (AUSF)
Policy Control Function (PCF)
Unified Data Management (UDM), which is functionally similar to 3G and 4G’s HSS
Application Function (AF), which can let applications retrieve data like latencies
Summary
This is the final post in the Introduction to Networks series of posts. It has been an extremely enlightening course. I have appreciated how much more extensive it was than I expected from an introductory course as I try to stay on top of the fast moving tech space.
The 8353009: Improve documentation for Windows AArch64 builds PR has a comment stating that “the BuildTools distribution of Visual Studio do not include aarch64-hosted compilers, so to be able to run native builds without the Prism emulation, you need to install the full Visual Studio, including the IDE.” This post describes how I determined this to be false.
Running bash configure --with-boot-jdk=<PATH> failed with the error that it could not find a C compiler:
...
checking for cacerts file... default
checking for cacerts source... default
checking for --enable-unlimited-crypto... enabled, default
checking for jni library path... default
configure: Using default toolchain microsoft (Microsoft Visual Studio)
configure: Found Visual Studio installation at /cygdrive/c/progra~2/micros~2/2022/BuildTools using well-known name
configure: Found Microsoft Visual Studio 2022
configure: Trying to extract Visual Studio environment variables for aarch64
configure: using /cygdrive/c/progra~2/micros~2/2022/BuildTools/vc/auxiliary/build/vcvarsarm64.bat
configure: Setting extracted environment variables for aarch64
checking that Visual Studio variables have been correctly extracted... ok
checking for cl... [not found]
configure: error: Could not find a C compiler.
configure exiting with result code 1
The TOOLCHAIN_FIND_COMPILER macro calls the UTIL_LOOKUP_TOOLCHAIN_PROGS macro to find the C compiler. I verified that the last argument is “cl” with an AC_MSG_NOTICE. At this point, I compared the TOOLCHAIN_PATH in config.log with that on a different ARM64 machine with a full VS install. Sure enough, it didn’t contain the bin/hostarm64/arm64 path with the buildtools setup, even though the path exists on disk. TOOLCHAIN_PATH is coming from VS_PATH in toolchain_microsoft.m4. Here is the build\windows-aarch64-server-slowdebug\configure-support\vs-env-aarch64\set-vs-env.sh file.
Notice that VS_PATH only has what VS_ENV_CMD added to the PATH! This was a clue that I need to take another step back – I realized that I couldn’t even run cl.exe in the developer command prompt! Then again, the command line for the terminal is:
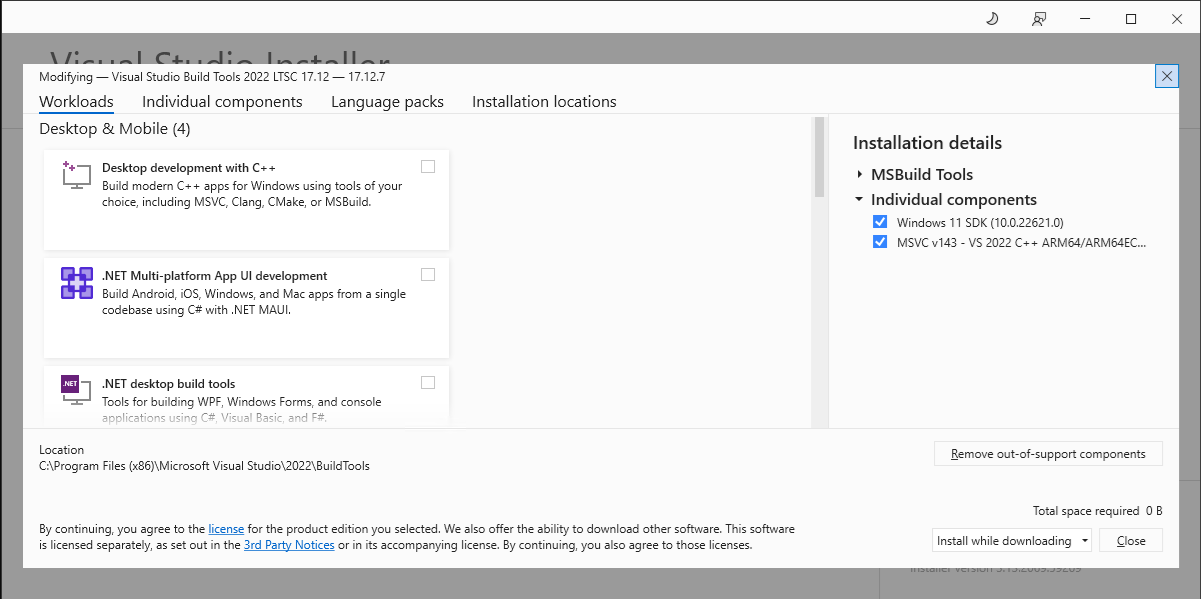
Changing the host architecture to arm64 did not help. I launched the VS installer and noticed that the “Desktop development with C++” workload was not installed so I must have been missing additional components.
Visual Studio Build Tools 2022 LTSC 17.12 Workloads
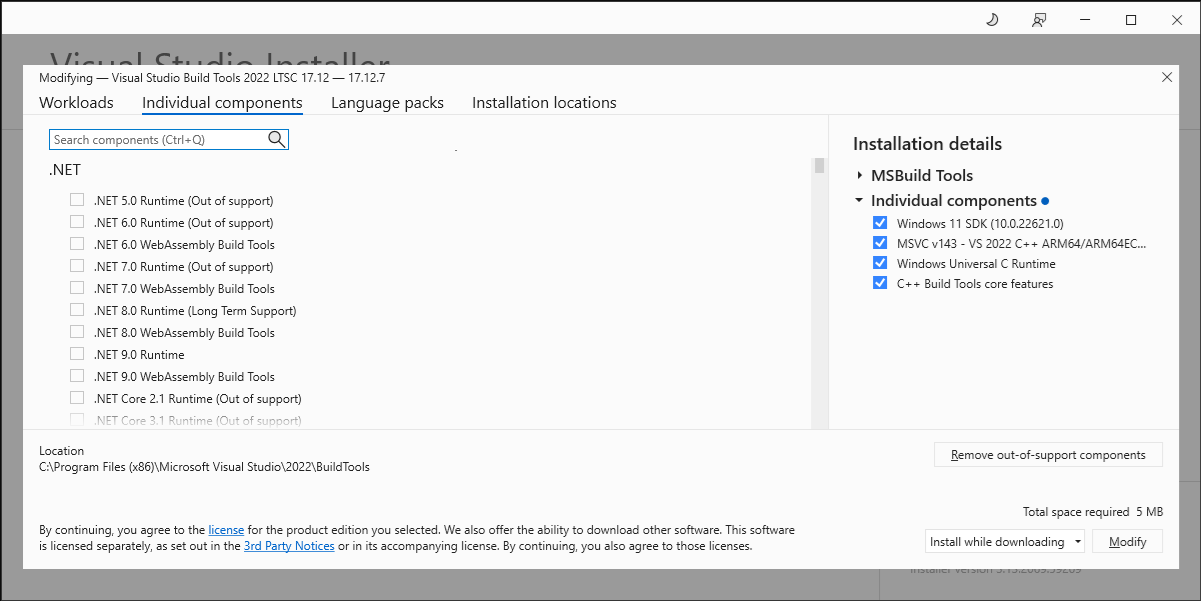
I didn’t want to install the whole workload though, just the necessary individual components. I noticed the C++ Build Tools core features component wasn’t installed so I selected it. The Windows Universal C Runtime component is automatically selected as well:
Visual Studio Build Tools 2022 LTSC 17.12 Individual Components
Once the installation completed, I could run cl.exe in the developer command prompt!
**********************************************************************
** Visual Studio 2022 Developer Command Prompt v17.12.7
** Copyright (c) 2022 Microsoft Corporation
**********************************************************************
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools>cl
Microsoft (R) C/C++ Optimizing Compiler Version 19.42.34441 for ARM64
Copyright (C) Microsoft Corporation. All rights reserved.
usage: cl [ option... ] filename... [ /link linkoption... ]
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools>
The VS installer log in %TEMP% contained these components:
Copilot informed me that the caret was the way to split a command across multiple lines in the Windows Command Prompt. This was the final command I used to complete the 8353009: Improve documentation for Windows AArch64 builds PR.
While learning about large language models, the issue of vanishing gradients came up. What is a gradient? I attempted to describe it as the difference between where you are and where you want to be (the target), which is given by the loss function. This led to the question of what exactly a loss function is. The video below from IBM Technology explains loss functions: a loss function is an evaluation metric (how well is the model performing) and/or a guide that directs the model’s learning process.
What is a Loss Function? Understanding How AI Models Learn
The primary reason for calculating the loss function is to guide the model’s learning process. It provides a numeric value that indicates how far off the model’s predictions are from the actual results. By analyzing the loss, the model’s parameters can be adjusted (optimization) since the loss function is a feedback mechanism to the model, telling it how well it is performing and where it needs to improve. – What is a Loss Function? Understanding How AI Models Learn
A smaller value of the loss function indicates that the performance of the model has improved.
The gradient of the loss function is useful because it enables algorithms to determine which adjustments (e.g. to weights) will result in a smaller loss. The next video on Gradient descent, how neural networks learn is a helpful introduction to how loss functions are used to guide learning.
Gradient descent, how neural networks learn | DL2
Backpropagation is the algorithm used to compute the gradient. This video from 3Blue1Brown is a helpful explanation of what backpropagation is:
Backpropagation, intuitively | DL3
Two important phenomena in gradient descent are the problems of vanishing and exploding gradients. The Vanishing & Exploding Gradient explained | A problem resulting from backpropagationvideo describes these problems as follows: vanishing gradients mean that updated weights earlier in the network barely change (stuck) which means that the rest of the network cannot really minimize the loss function (i.e. learn). Exploding gradients mean that the earlier weights now increase so much that the optimal value of the loss function will never be achieved because weights become too big too quickly.
Vanishing & Exploding Gradient explained | A problem resulting from backpropagation
The focus of part 3 of this series is on the different types of wired networks. A key aspet of many networks is that QoS is just one concern, another key issue being how to meet guarantees for delivery of voice services. How is voice delivered? Integrated Services Digital Network (ISDN) is an international standard for voice, video, and data transmission over digital telephone or copper lines. It has two service levels. The first is Basic Rate Interface (BRI), which supports 2 bearer channels at 64kbps each and 1 D channel at 16 kbps. The second is the Primary Rate Interface (PRI), which supports 23 bearer channels (in the US) at 64 kbps each and 1 D channel at 16 kbps. The signaling/data (D) channel runs the ISDN signaling protocol based on Q.931. This video is a good high level introduction of ISDN. T1 and ISDN are used in access networks, together with technologies like IP and MPLS.
ISDN – Integrated Services Digital Network
Optical Networks
In newer generations of networks, the core is fiber (instead of copper) because it can deliver terabits per second. Installation and management of fiber networks is also much easier than copper networks. Fiber optic signals are analog – (in the infrared range).
What is the ELECTROMAGNETIC SPECTRUM
Light sources used for fiber optic communication include light-emitting diodes (LEDs), laser diodes, vertical cavity surface emitting lasers (VCSELs), Fabry-Perot lasers, and distributed feedback lasers.
How LED Works – Unravel the Mysteries of How LEDs Work!
The packet transport network is another key piece to understand. Customers send traffic to metro access, aggregation, and core portions of the network where voice and data are converged. In the packet core, wavelengths are being added and dropped by add-drop multiplexers. There are several types of ADMs with links to explanations about them from various vendors:
Open ROADM, which works to address the fact that optical systems have been proprietary (e.g. because SD FEC algorithms) on transponders are not interoperable and there are proprietary control loops between transponders and other optical components).
The next video gave me a better understanding of customer concerns with ROADMs and FOADMs.
Tutorial: To ROADM or Not to ROADM: When does a FOADM make sense in your optical network?
Other major types of network components include amplifiers, regenerators, and equalization nodes. Transponders map client side signals to wavelengths for high speed transport. They can be contained in a field-replaceable unit (FRU). Common types of pluggable optics include SFP+ (Small Form-factor Pluggable), CFP4, and QSFP28. Amplification is an analog process of boosting signal strength and is done in the optical domain (no conversion to electrical). Any impairments in the signal are boosted as well. A single pump laser is used for this. Regeneration can reshape and retime the optical signal but requires conversion to the electrical domain then back to the optical domain, making it more expensive to implement.
How a Fiber Laser Works
Major types of amplifiers in optical networks include EDFA (Erbium Doped Fiber Amplifer), Raman amplifier, and Hybrid Raman-EDFA amplifier. These are great explanations of these amplifiers:
Working Principle of Erbium Doped Fiber Amplifier (EDFA)
The EDFA – how it was developed.
Wavelength Selective Switch (WSS) was first implemented using MEMS but did’t work well because the hinges would fail. Liquid Crystal on Silicon (LCoS) is now commonly used to implement WSS since it has no moving parts. It can also support Flexgrid.
What is LCoS Based Wavelength Selective Switch – FO4SALE.COM
Optical patch panels are another component in fiber networks. They are used to join optical fibers where a connect/disconnect capability is required.
Handling Failure
There are 2 types of protection in networks:
Network protection: ensures that customer SLAs are met by preventing failures. Optical protection examples include mesh restoration (GMPLS, SDN), SNCP (OTN), UPSR & BLSR for SONET, and 1+1 or 1:1 circuits (active vs inactive backup circuit). Packet protection examples include MPLS fast reroute, LAG, G.8031, G.8032.
Equipment protection: focuses on protecting individual nodes.
I couldn’t emphasize this enough: this is such a broad field with so many technologies! What an introduction to networking!
The previous post introduced different types of networks and some of their architectural details. In this post, we look at the biggest problem network engineers work on: congestion. How are networks designed to address it? The professor starts tackling this area with a discussion of Quality of Service (QoS). Quality is defined in terms of the underlying requirements e.g. throughput, delay, jitter, packet loss, service availability, and per-flow sequence preservation. Services can be best effort, or other classes like gold service. Cisco’s Quality of Service (QoS) document discusses four levels of metal policy (platinum, gold, silver, and bronze), for example.
Class of Service (CoS) is a traffic classification that enables different actions to be taken on individual classes of traffic. Contrast this to type of service (ToS), which is a specific field in the IPv4 header (used to implement CoS). Juniper Networks post on Understanding Class of Service (CoS) Profiles equates QoS and CoS, but the professor explains that QoS is a more abstract concept than CoS.
QoS is a set of actions that the network takes to deliver the right delay, throughput, etc. QoS timeframes affect the way congestion is handled. For example, scheduling and dropping techniques and per-hop queuing are useful for the low millisecond time regime common in web traffic. Congestion over hundreds of milliseconds typically affects TCP (e.g. round trip times, closed-loop feedback) and this is addressed via methods like active queue management (AQM) and congestion control techniques like random early detection (RED). Congestion that occurs in the tens of seconds to minutes range is addressed by capacity planning.
How is QoS achieved in the data and control planes? By queuing, scheduling, policing, and dropping. The roles of the data and control planes are quite extensive as per the router diagram used to describe them. This is without getting into the details of the management plane e.g. the element management systems (per node) and the network management systems they communicate with. Control plane QoS mechanisms handle admission control and resource reservation and are typically implemented in software. Resource Reservation Protocol (RSVP) is the protocol mostly used in practice for control plane QoS. There are many explanations on RSVP, e.g. this Introduction to RSVP and this RSVP Overview. The primary QoS architectures are integrated services (Intserv) and differentiated services (Diffserv). Intserv uses RSVP and although it doesn’t scale, it is useful when guaranteed service is required.
We start a deep dive into the QoS techniques with queuing. There are different types of queues: first come first served (FCFS/FIFO), priority queues, and weighted queues. Packet schedulers can have a mix of these approches, e.g. 1 priority queue and N other weighted queues. Performance modeling can be done on queues. For voice traffic, the distribution of the arrival rate of traffic is a Poisson distribution. Therefore, the delay of packets and the length of the queue can be accurately modeled/predicted! See M/M/1 queues as a starting point (M/M/1 is Kendall notation and is more fully described in the next video).
Queuing Theory Tutorial – Queues/Lines, Characteristics, Kendall Notation, M/M/1 Queues
Data Plane QoS Mechanisms
These data plane QoS mechanisms are applied at each network node: classification, marking, policing and shaping, prioritization, minimum rate assurance. Below are more details about each.
Classification
This is the process of identifying flows of packets and grouping individual traffic flows into aggregated streams such that actions can be applied to those flow streams. Up to this point, I have had a vague idea of what a flow is but not a proper definition. The instructor defines a flow as a 5-tuple of source & destination IP addresses and TCP/UDP ports and a transport protocol. What is a Network Traffic Flow? discusses various ways of defining a flow, and this is just one of many. Classification needs to avoid fragmentation because the 5-tuple information is only in the first packet. There are 4 ways of classifying traffic:
Simple classification – the use of fields designed for QoS classification in IP headers e.g. the type of service (TOS) byte in IPv4. There are complications with using the DTRM bits of the TOS (e.g. minimizing delay and maximizing throughput could conflict).
Implicit classification – done without inspecting packet header or content, e.g. by examining layer 1 or 2 identifiers.
Complex classification – using fields not designed for QoS classification or layer 2 criteria like MAC addresses.
This is simply setting the fields assigned for QoS classification in IP packet headers (DSCP field) or MPLS packet headers (EXP field).
Source marking is applied at the source of the packets
Ingress marking: used when source cannot mark correctly or cannot be trusted to do so.
Rate Enforcement
This is done to avoid congestion. Policing is a mechanism to ensure that a traffic stream does not exceed a defined maximum rate. It stands in constrast to shaping, which is typically accomplished by queuing (delays traffic, never drops it). One type of policer is the token bucket policer. It never delays traffic and cannot reorder or reprioritize traffic. See Cisco’s Policing and Shaping Overview and QoS Policing documents for details. This is one of the rate limiting algorithms discussed in the video below (I found this video’s explanation more intuitive).
Five Rate Limiting Algorithms ~ Key Concepts in System Design
The next stage is prioritization of the traffic. 4 possible approaches: with prioritiy queues, e.g. where VoIP traffic always has highest priority, other queues can be starved by the scheduler. Weighted round robbin will take more packets from the high priority queues but still cycle through the other queues, taking fewer packets from them. Weighted bandwidth scheduling considers the packet sizes instead of just packet counts per queue (e.g. just taking 1 packet from a low priority queue can have negative impact if the packet is huge). Deficit round robbin is the one used in practice. It keeps track of the history of the number of packets services, and not just instantaneous values. I found the next video to expand on these brief explanations of scheduling algorithms.
How Do Schedulers in Routers Work? Understanding RR, WRR, WFQ, and DRR Through Simple Examples
One of the points that came up in discussion was that the schedulers use Run-to-completion scheduling, which means that a packet must be fully processed before starting on another packet. Routers have an interface FIFO (Tx buffer) on the physical link. When it fills up, this signals to the scheduler that there may be congestion downstream, thereby allowing for back pressure flow control. There is also multi-level strict policy queuing which allows for multiple priority queues instead of just 1 (e.g. voice & video) but not as common today.
Routers also drop packets to prevent unacceptable delays caused by buffering too many packets. There are different dropping strategies, e.g. tail dropping (dropping from the back of the queue), weighted tail dropping (>1 queue limit via heuristics), and head dropping (rare).
Active queue management (AQM) is a congestion avoidance technique. It works by detecting congestion before queues overflow. These are some techniques for AQM:
These QoS mechanisms operate in the context of an overriding architecture, integrated services (Intserv) or differentiated services (Diffserv). IntServ can be used in the financial industry or medical health facilities, for example. These are delay sensitive applications where unbounded scaling is not a real requirement. IntServ explicitly manages bandwidth resources on a per flow basis. DiffServ was developed to support (as the name suggests) differentiated treatment of packets in large scale environments. It does this using a 6-bit differentiated services code point (DSCP) in the IPv4 ToS header or the IPv6 traffic class octet. Classification and conditioning happen at the edge of the DiffServ domain. Actions are performed on behavior aggregates (contrast this to the per flow actions of IntServ). The next technology we learn about is Multiprotocol Label Switching, defined as follows on Wikipedia:
MPLS is similar to IntServ in that it lets you define an end-to-end path through the network for traffic but without reserving resources. It is a hop by hop forwarding mechanism, which stands in contrast to IP which works by making next hop routing decisions without regard to the end-to-end path taken by the packets. MPLS can be deployed on any layer 2 technology (multiprotocol). Benefits of MPLS include fast rerouting in case of failures and providing QoS support. One of the settings in which MPLS is used is in SD-WAN. This article provides a helpful contrast: What is the difference between SD-WAN and MPLS? These are the main applications of MPLS:
Traffic Engineering: allows network administrator to make the path deterministic (normal hop-by-hop routing is not). In other words, a frame forwarding policy can be used instead of relying on dynamic routing protocols.
QoS: the MPLS EXP bits are used for marking traffic per the labels.
This is quite the array of topics, especially for an introduction to networks course. I have a greater appreciation of how broad this space is.
I’m taking an online introductory course on networks. I have been surprised by how much ground this course is covering. I didn’t expect to cover wireless (mobile) networks, for example. I looked for videos on some of the topics to learn more, e.g. 4g network architecture – YouTube. Networking is turning out to be much cooler and more interesting than I thought possible. This post is a compilation of all the key topics introduced in the course (in the general order they were introduced, but not particularly organized into a coherent story).
My main takeaway from this first video is that 4G networks are entirely packet switched (basic, but new to me).
4G LTE Network Architecture Simplified
The next video on how messages are transmitted to the cell phone tower is insightful as well. I appreciated the high-level discussion of antennas.
How WiFi and Cell Phones Work | Wireless Communication Explained
The concept of control plane and data plane came up as well. One advantage of this separation as per the overview below are independent evolution and development of each (e.g. control software can be upgraded without changing the hardware).
M2.1: Overview of Control and Data Plane Separation
5G Service Based Architecture | Telecoms Bytes – Mpirical
Then of course there are the fundamental concepts of throughput, delay, and packet loss error. Jim Kurose’s book (and video below) covers these topics but it’s been a while since I read that book.
The professor also clarified the difference between bandwidth and throughput. The next video briefly touches on this distinction:
The course has also introduced me to the concept of spectral efficiency as part of understanding the difference between bandwidth and throughput. There is no shortage of concepts to learn about, from the different types of lines like T1 and T3 to bit robbing to the existence of network interface devices. The video below is good intro to T1.
DS1 (T1) Fundamentals
There was also a discussion about cable networks, with an onslaught of concepts like Hybrid fiber-coaxial. This Cable 101 video is a helpful resource.
The HFC Cable Systems Introduction video below starts out with a comparison of coax and fiber then explains the flow of signals from the core network to the home.
HFC Cable Systems Introduction
I still need to learn more information about the Cable modem termination system (CMTS) and the next resource is perfect. It mentions CMTS vendors like Arris, Cisco, and Motorola, which inspires me to look up the Cisco CMTS.
Cable Modem Termination System Tutorial (CMTS)
I have never researched how most of these systems work so I am greatly appreciating this introduction to networks course! Here’s a video on how cable modems work, including their interactions with the CMTS.
How Cable Modems Work
The communication between the CMTS and the CMs is done via DOCSIS. Here is the reference I found with insight into DOCSIS.
DOCSIS® 3.1 – An Overview
Something I picked up is that CableLabs does a lot of the research for these systems. Other concepts to know include wavelength-division multiplexing (WDM), which was used in the traditional coax networks. The following explanation is an example of WDM in fiber.
Next, we get into the 7-layer OSI model. The example given for the physical layer is SONET technology. Another foray into T1 technology reveals the fact that bipolar transmission is used for T1 since it is more power efficient.
Multiplexing is the next interesting topic introduced. I have included some videos below on the different types of multiplexing employed in communications.
FDM involves modulating message signals over carrier frequencies then using bandpass filters to extract the individual signals.
The course also addresses transmission fundamentals like the difference between bit rate and baud rate, the Shannon–Hartley theorem, the Nyquist–Shannon sampling theorem, modulation, modems, and codecs. I have compiled a few videos covering these topics below.
Here is an explanation of the Shannon–Hartley theorem:
Channel Capacity by Shannon-Hartley | Basics, Proof & Maximum Bandwidth Condition
We then start getting into network addressing. One of the important concepts here is how the exhaustion of IPv4 addresses is handled: private IP addresses, DHCP, subnetting, and IPv6. One particularly interesting point was the difference between IPv4 and IPv6 headers:
In a discussion of the impact of TCP on throughput, the professor called out TCP global synchronization as an issue that networks need to avoid. Here’s one video about it.
Avoiding packet reordering is another important aspect of TCP. The contrast with UDP is especially interesting when other protocols like Google’s QUIC are designed. The RTP protocol (a relative of UDP, informally speaking) is used for VoIP. This is a good description of RTP: