cd ~/java/binaries
mkdir spark
cd spark
curl -Lo spark-3.4.0-bin-hadoop3.tgz https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
tar xzf spark-3.4.0-bin-hadoop3.tgz
cd spark-3.4.0-bin-hadoop3
Spark needs JAVA_HOME to be set (otherwise the first message displayed will be ERROR: JAVA_HOME is not set and could not be found).
Next, I started the Spark shell by running this command as per the Quick Start docs:
./bin/spark-shell
Notice that the same Hadoop warning from Diagnosing Hadoop Native Library Load Failures showed up again! However, we have already seen that the Hadoop logging level can be customized. The key question now is how to enable DEBUG logging in spark
saint@ubuntuvm:~/java/binaries/spark/spark-3.4.0-bin-hadoop3$ ./bin/spark-shell
23/06/01 10:31:38 WARN Utils: Your hostname, ubuntuvm resolves to a loopback address: 127.0.1.1; using 172.18.28.45 instead (on interface eth0)
23/06/01 10:31:38 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/06/01 10:31:44 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://ubuntuvm.mshome.net:4040
Spark context available as 'sc' (master = local[*], app id = local-1685637105440).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.0
/_/
Using Scala version 2.12.17 (OpenJDK 64-Bit Server VM, Java 17.0.6)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
The classpath augmentation doc (Using Spark’s “Hadoop Free” Build) is what informs me that the way Spark uses Hadoop can be customized by entries in conf/spark-env.sh. Unfortunately, there are no log level settings in the spark-env.sh.template file in that directory. After a bit of a winding journey, I discover that the way to customize the logging level is to first create a conf/log4j2.properties file by running:
Next, change the logging level by updating this line:
logger.repl.level = warn
Launching the Spark shell now displays a much more informative error message. It is now evident that the paths being searched for native libraries do not include the path we need.
23/06/01 11:16:31 DEBUG NativeCodeLoader: Trying to load the custom-built native-hadoop library...
23/06/01 11:16:31 DEBUG NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path: [/usr/java/packages/lib, /usr/lib64, /lib64, /lib, /usr/lib]
23/06/01 11:16:31 DEBUG NativeCodeLoader: java.library.path=/usr/java/packages/lib:/usr/lib64:/lib64:/lib:/usr/lib
23/06/01 11:16:31 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
The required flag is the –driver-library-path. Sounds like the extraLibraryPath options didnt’ work because the JVM has already started by the time those are being processed.
It was the SPARK-7261 pull request that led me to look for the log4j2.properties file. Changing rootLogger.level did not have any effect but scrolling through revealed the key line setting logger.repl.level.
When running this test code, I noticed this warning (first message displayed):
2023-05-31 12:31:33,686 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Checking for Loadable Native Libraries
The Apache Hadoop 3.3.5 – Native Libraries Guide explains that there is a NativeLibraryChecker that can be run using the command bin/hadoop checknative -a to show which native libraries can/cannot be loaded.
saint@ubuntuvm:~/java/binaries/hadoop/hadoop-3.3.5$ find . -name lib*.so
./lib/native/libhadoop.so
./lib/native/libhdfspp.so
./lib/native/libhdfs.so
./lib/native/libnativetask.so
saint@ubuntuvm:~/java/binaries/hadoop/hadoop-3.3.5$ uname -a
Linux ubuntuvm 5.19.0-41-generic #42~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Tue Apr 18 17:40:00 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
saint@ubuntuvm:~/java/binaries/hadoop/hadoop-3.3.5$ bin/hadoop checknative -a
2023-05-31 13:36:04,467 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
zstd : false
bzip2: false
openssl: false
ISA-L: false
PMDK: false
2023-05-31 13:36:04,711 INFO util.ExitUtil: Exiting with status 1: ExitException
Diagnosing Native Library Load Errors
My assumption when seeing that none of these native libraries could be loaded was that I needed to install all those dependencies. I started with lib64z.
saint@ubuntuvm:~/java/binaries/hadoop/hadoop-3.3.5$ sudo apt install lib64z1
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
gcc-12-base:i386 krb5-locales libc6:i386 libc6-amd64:i386 libcom-err2:i386 libcrypt1:i386
libgcc-s1:i386 libgssapi-krb5-2 libgssapi-krb5-2:i386 libidn2-0:i386 libk5crypto3 libk5crypto3:i386
libkeyutils1:i386 libkrb5-3 libkrb5-3:i386 libkrb5support0 libkrb5support0:i386 libnsl2:i386
libnss-nis:i386 libnss-nisplus:i386 libssl3 libssl3:i386 libtirpc3:i386 libunistring2:i386
Suggested packages:
glibc-doc:i386 locales:i386 krb5-doc krb5-user krb5-doc:i386 krb5-user:i386
The following NEW packages will be installed:
gcc-12-base:i386 krb5-locales lib64z1:i386 libc6:i386 libc6-amd64:i386 libcom-err2:i386
libcrypt1:i386 libgcc-s1:i386 libgssapi-krb5-2:i386 libidn2-0:i386 libk5crypto3:i386
libkeyutils1:i386 libkrb5-3:i386 libkrb5support0:i386 libnsl2:i386 libnss-nis:i386
libnss-nisplus:i386 libssl3:i386 libtirpc3:i386 libunistring2:i386
The following packages will be upgraded:
libgssapi-krb5-2 libk5crypto3 libkrb5-3 libkrb5support0 libssl3
5 upgraded, 20 newly installed, 0 to remove and 85 not upgraded.
Need to get 10.3 MB/12.2 MB of archives.
After this operation, 38.1 MB of additional disk space will be used.
Do you want to continue? [Y/n]
Interestingly, rerunning checknative still showed false for all the native libraries! Next step was to inspect how the checknative argument is handled. It invokes the hadoop/NativeLibraryChecker.java class, which in turn calls the hadoop/NativeCodeLoader.java. One of the most important observations in the latter file is the additional debug logging available when the library doesn’t load!
The debug output is much now more informative! Notice the warning about the possible platform mismatch of the native library!
saint@ubuntuvm:~/java/binaries/hadoop/hadoop-3.3.5$ bin/hadoop --loglevel DEBUG checknative -a
2023-05-31 14:47:32,624 DEBUG util.NativeCodeLoader: Trying to load the custom-built native-hadoop library...
2023-05-31 14:47:32,625 DEBUG util.NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: /home/saint/java/binaries/hadoop/hadoop-3.3.5/lib/native/libhadoop.so.1.0.0: /home/saint/java/binaries/hadoop/hadoop-3.3.5/lib/native/libhadoop.so.1.0.0: cannot open shared object file: No such file or directory (Possible cause: can't load AARCH64-bit .so on a AMD 64-bit platform)
2023-05-31 14:47:32,625 DEBUG util.NativeCodeLoader: java.library.path=/home/saint/java/binaries/hadoop/hadoop-3.3.5/lib/native
2023-05-31 14:47:32,625 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-05-31 14:47:32,836 DEBUG util.Shell: setsid exited with exit code 0
Native library checking:
hadoop: false
zlib: false
zstd : false
bzip2: false
openssl: false
ISA-L: false
PMDK: false
2023-05-31 14:47:32,847 DEBUG util.ExitUtil: Exiting with status 1: ExitException
1: ExitException
at org.apache.hadoop.util.ExitUtil.terminate(ExitUtil.java:381)
at org.apache.hadoop.util.ExitUtil.terminate(ExitUtil.java:369)
at org.apache.hadoop.util.NativeLibraryChecker.main(NativeLibraryChecker.java:154)
2023-05-31 14:47:32,856 INFO util.ExitUtil: Exiting with status 1: ExitException
To determine the architecture for which the shared library was compiled, I started with the objdump -f command as suggested by a StackOverflow post. However, it outputs architecture: UNKNOWN!, which isn’t very useful. The file command from the same post proves to be exactly what I need.
saint@ubuntuvm:~/java/binaries/hadoop/aarch64/hadoop-3.3.5$ objdump -f lib/native/libhadoop.so
lib/native/libhadoop.so: file format elf64-little
architecture: UNKNOWN!, flags 0x00000150:
HAS_SYMS, DYNAMIC, D_PAGED
start address 0x0000000000005b80
saint@ubuntuvm:~/java/binaries/hadoop/aarch64/hadoop-3.3.5$ file lib/native/libhadoop.so
lib/native/libhadoop.so: symbolic link to libhadoop.so.1.0.0
saint@ubuntuvm:~/java/binaries/hadoop/aarch64/hadoop-3.3.5$ file lib/native/libhadoop.so.1.0.0
lib/native/libhadoop.so.1.0.0: ELF 64-bit LSB shared object, ARM aarch64, version 1 (SYSV), dynamically linked, BuildID[sha1]=19fbe9b0a7449eb05b687721548251af752b869f, with debug_info, not stripped
Turns out I was using an x86-64 Ubuntu VM instead of the aarch64 Ubuntu VM I had created so naturally, hadoop couldn’t load the aarch64 hadoop native library! For the VM I had been using, I needed to get the hadoop build by running:
Checking the loading status of the native libraries now indicates that the hadoop native library can be successfully loaded:
saint@ubuntuvm:~/java/binaries/hadoop/x64/hadoop-3.3.5$ bin/hadoop checknative -a
2023-05-31 14:58:40,869 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
2023-05-31 14:58:40,877 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
2023-05-31 14:58:40,887 WARN erasurecode.ErasureCodeNative: Loading ISA-L failed: Failed to load libisal.so.2 (libisal.so.2: cannot open shared object file: No such file or directory)
2023-05-31 14:58:40,887 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
2023-05-31 14:58:41,035 INFO nativeio.NativeIO: The native code was built without PMDK support.
Native library checking:
hadoop: true /home/saint/java/binaries/hadoop/x64/hadoop-3.3.5/lib/native/libhadoop.so.1.0.0
zlib: true /lib/x86_64-linux-gnu/libz.so.1
zstd : true /lib/x86_64-linux-gnu/libzstd.so.1
bzip2: true /lib/x86_64-linux-gnu/libbz2.so.1
openssl: false Cannot load libcrypto.so (libcrypto.so: cannot open shared object file: No such file or directory)!
ISA-L: false Loading ISA-L failed: Failed to load libisal.so.2 (libisal.so.2: cannot open shared object file: No such file or directory)
PMDK: false The native code was built without PMDK support.
2023-05-31 14:58:41,056 INFO util.ExitUtil: Exiting with status 1: ExitException
Switching to the aarch64 Ubuntu VM also showed the aarch64 hadoop native library being successfully loaded on that platform. In hindsight, the 386 architecture references when I installed lib64z could have been a warning sign if I wasn’t just blasting my way through running these commands.
In the last post, I described the straightforward process of setting up and Ubuntu VM in which to run Hadoop. Once you can successfully run the Hadoop MapReduce example in the MapReduce Tutorial, you may be interested in examining the source code using an IDE like Eclipse. To do so, install eclipse:
sudo apt-get install eclipse-platform
Some common Eclipse settings to adjust:
Show line numbers (Window > Preferences > General > Editors > Text Editors > Show Line Numbers
To generate an Eclipse project for the Hadoop source code, the src/BUILDING.txt file lists these steps (which we cannot yet run):
cd ~/hadoop-2.7.4/src/hadoop-maven-pluggins
mvn install
cd ..
mvn eclipse:eclipse -DskipTests
To be able to run these commands, we need to install the packages required for building Hadoop. They are also listed in the src/BUILDING.txt file. For the VM we set up, we do not need to install the packages listed under Oracle JDK 1.7. Instead, run these commands to install Maven, native libraries, and ProtocolBuffer:
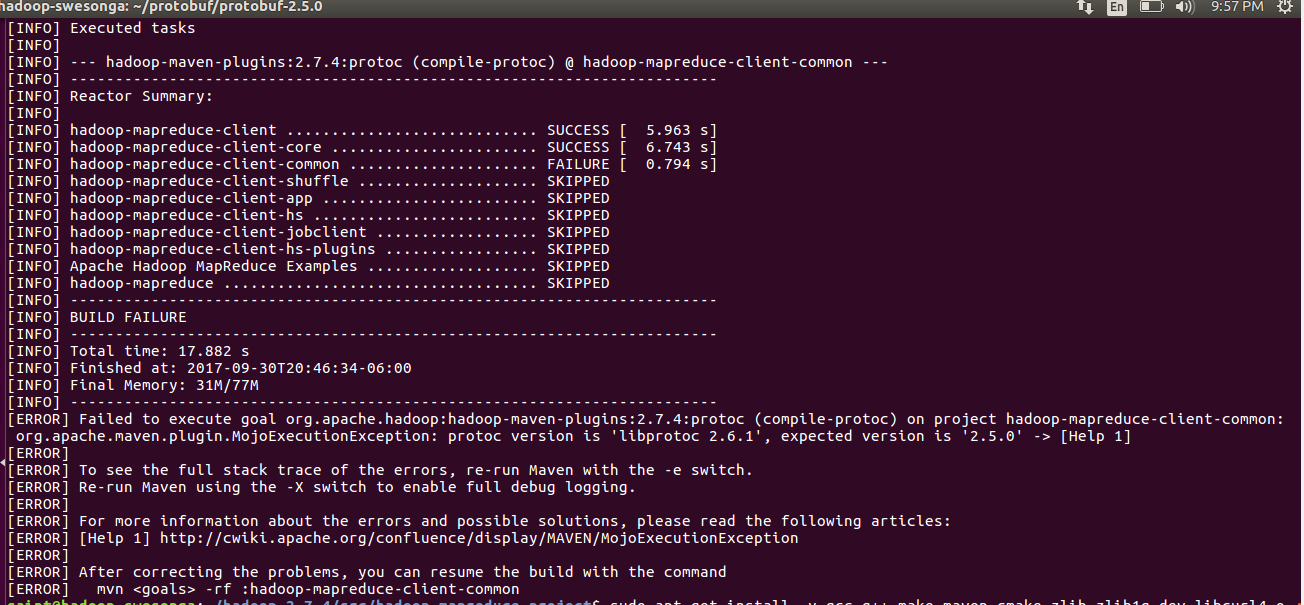
Now here’s where things get interesting. The last command installs version 2.6.1 of the ProtocolBuffer. The src/BUILDING.txt file states that version 2.5.0 is required. Turns out they aren’t kidding – if you try generating the Eclipse project using version 2.6.1 (or some non 2.5.0 version), you’ll get an error similar to this one:
As suggested here and here, you can check the version by typing:
mkdir ~/protobuf
cd ~/protobuf
wget https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz
tar xvzf protobuf-2.5.0.tar.gz
cd protobuf-2.5.0
Now follow the instructions in the README.txt file to build the source code.
./configure --prefix=/usr
make
make check
sudo make install
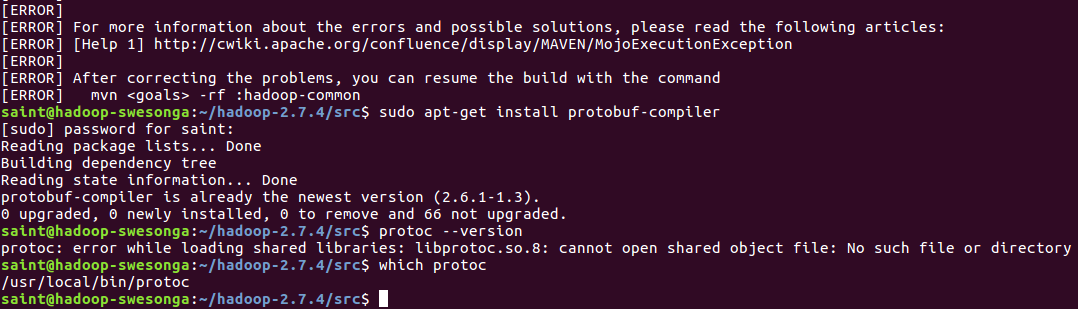
protoc --version
The output from the last command should now be “libprotoc 2.5.0“. Note: you most likely need to pass the –prefix option to ./configure to avoid errors like the one below.
Now we can finally generate the Eclipse project files for the Hadoop sources.
cd ~/hadoop-2.7.4/src/hadoop-maven-plugins
mvn install
cd ..
mvn eclipse:eclipse -DskipTests
Once project-file generation is complete:
Type eclipse to launch the IDE.
Go to the File > Import… menu option.
Select the Existing Projects into Workspace option under General.
Browse to the ~/hadoop-2.7.4/src folder in the Select root directory: input. A list of the projects in the src folder should be displayed.
Click Finish to import the projects.
You should now be able to navigate to the WordCount.java file and inspect the various Hadoop classes.
As part of my Dynamic Big Data course, I have to set up a distributed file system to experiment with various mapreduce concepts. Let’s use Hadoop since it’s widely adopted. Thankfully, there are instructions on how to set up Apache Hadoop – we’re starting with a single cluster for now.
Once installation is complete, log onto the Ubuntu OS. Set up shared folders and enable the bidirectional clipboard as follows:
From the VirtualBox Devices menu, choose Insert Guest Additions CD image… A prompt will be displayed stating that “VBOXADDITIONS_5.1.26_117224” contains software intended to be automatically started. Just click on the Run button to continue and enter the root password. When the guest additions installer completes, press Return to close the window when prompted.
From the VirtualBox Devices menu, choose Shared Clipboard > Bidirectional. This enables two way clipboard functionality between the guest and host.
From the VirtualBox Devices menu, choose Shared Folders > Shared Folders Settings… Click on the add Shared Folder button and enter a path to a folder on the host that you would like to be shared. Optionally select Auto-mount and Make Permanent.
Open a terminal window. Enter these commands to mount the shared folder (assuming you named it vmshare in step 3 above):
cd ~/Downloads
wget http://apache.cs.utah.edu/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
mkdir ~/hadoop-2.7.4
tar xvzf hadoop-2.7.4.tar.gz -C ~/
cd ~/hadoop-2.7.4
If you skip setting up this export, running bin/hadoop will give this error:
Error: JAVA_HOME is not set and could not be found.
Note: I found that setting JAVA_HOME=/usr caused subsequent processes (like generating Eclipse projects from the source using mvn) to fail even though the steps in the tutorial worked just fine.
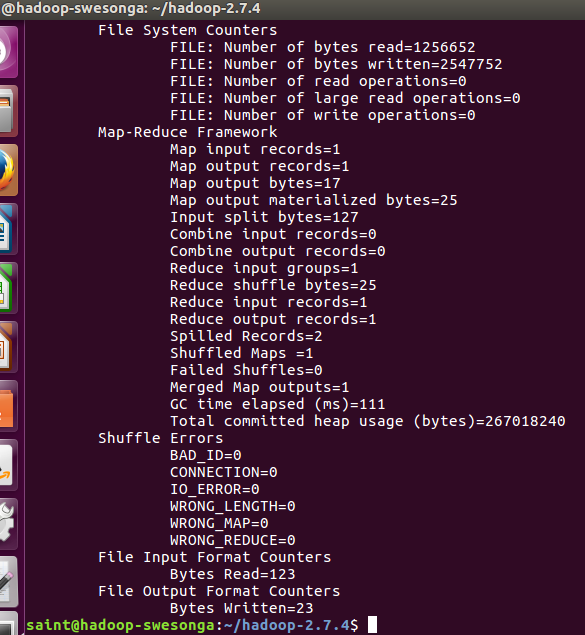
To verify that Hadoop is now configured and ready to run (in a non-distributed mode as a single Java process), execute the commands listed in the tutorial.
The bin/hadoop jar command runs the code in the .jar file, specifically the code in Grep.java, passing it the last 3 arguments. The output should resemble this summary:
If you’re interested in the details of this example (e.g. to inspect Grep.java), examine the src subfolder. If you don’t need the binaries and just want to look at the code, you can wget it from a download mirror, e.g.: